
Czy zdarzyło Ci się kiedyś otworzyć stronę internetową i zamiast polskich znaków diakrytycznych (jak ą, ę, ć, ł, ń, ó, ś, ź, ż) zobaczyć irytujące "krzaczki" lub inne dziwne symbole? To niezwykle powszechny problem, z którym boryka się wielu twórców stron, zwłaszcza tych początkujących. Jako Bruno Konieczny, z doświadczenia wiem, że ten błąd potrafi frustrować, ale mam dla Ciebie dobrą wiadomość: jego rozwiązanie jest zazwyczaj proste i sprowadza się do kilku kluczowych kroków, bazujących na współczesnych standardach HTML5 i kodowaniu UTF-8. W tym artykule pokażę Ci, jak raz na zawsze pozbyć się "krzaczków" z Twoich stron.
Poprawne wyświetlanie polskich znaków kluczowe kroki do eliminacji "krzaczków" na Twojej stronie
- Głównym rozwiązaniem jest umieszczenie tagu
w sekcjidokumentu HTML. - Konieczne jest fizyczne zapisanie pliku HTML w kodowaniu UTF-8 w wybranym edytorze kodu.
- Należy unikać przestarzałych kodowań, takich jak ISO-8859-2 czy Windows-1250, na rzecz uniwersalnego UTF-8.
- Upewnij się, że używane czcionki (zwłaszcza niestandardowe) obsługują rozszerzony zestaw znaków łacińskich (
latin-extended). - W rzadkich przypadkach problem może leżeć w konfiguracji serwera WWW, która nadpisuje ustawienia kodowania.
Zrozum, dlaczego Twoja strona "krzaczy"
Zanim przejdziemy do konkretnych rozwiązań, warto zrozumieć, dlaczego w ogóle pojawiają się "krzaczki". Komputery i przeglądarki internetowe nie rozumieją bezpośrednio liter czy symboli tak jak my. Zamiast tego, każdy znak jest reprezentowany przez liczbę. Kodowanie znaków to nic innego jak mapa, która przypisuje konkretną liczbę do konkretnego znaku. Jeśli przeglądarka próbuje wyświetlić tekst, który został zapisany w jednym kodowaniu (np. UTF-8), ale interpretuje go według innej mapy (np. Windows-1250), wtedy dochodzi do pomyłki. Zamiast "ą" widzimy wtedy "±" lub inny, niezrozumiały symbol. To właśnie jest ten moment, gdy pojawiają się "krzaczki", a problemem jest po prostu niezgodność w interpretacji kodu.
Krótka historia polskich "ogonków" w internecie: Od ISO-8859-2 do globalnego standardu UTF-8
W początkach internetu, zanim UTF-8 stało się dominującym standardem, dla różnych języków używano różnych kodowań. Dla języka polskiego popularne były dwa: ISO-8859-2 (znane też jako Latin-2) oraz Windows-1250. Oba te kodowania były w stanie poprawnie wyświetlać polskie znaki diakrytyczne. Problem polegał na tym, że były one "lokalne" ISO-8859-2 było standardem międzynarodowym dla Europy Środkowej i Wschodniej, a Windows-1250 było specyficzne dla systemów Microsoft Windows. To prowadziło do sytuacji, gdzie strona poprawnie wyświetlała się na jednym komputerze, a na innym już nie, w zależności od domyślnych ustawień przeglądarki czy systemu operacyjnego. Na szczęście, wraz z rozwojem internetu, pojawił się uniwersalny standard: UTF-8. UTF-8 to kodowanie, które jest w stanie reprezentować praktycznie każdy znak z każdego języka świata, co czyni je globalnym i rekomendowanym rozwiązaniem. Dzięki niemu, zamiast martwić się o specyficzne kodowania dla każdego języka, możemy po prostu używać jednego, który działa wszędzie.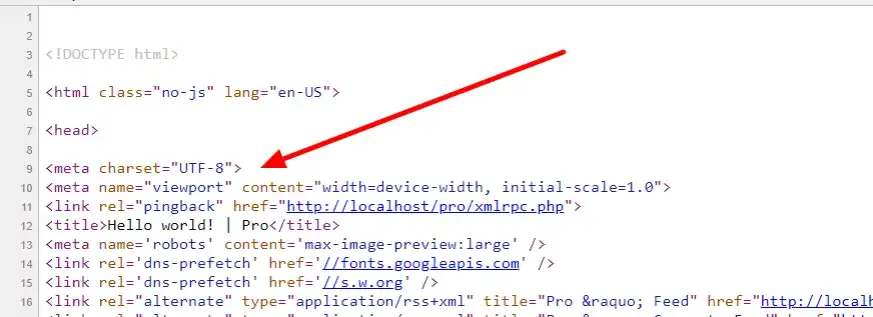
Złoty standard HTML5: Jedna linijka kodu rozwiązuje większość problemów
Współczesny standard HTML5 znacząco uprościł deklarowanie kodowania znaków. Jeśli chcesz, aby Twoja strona wyświetlała polskie znaki poprawnie, w zdecydowanej większości przypadków wystarczy jedna, prosta linijka kodu. To jest właśnie to "magiczne zaklęcie", które eliminuje "krzaczki" i pozwala Twojej treści zabłysnąć w pełnej krasie.
Krok po kroku: Gdzie dokładnie wkleić magiczny tag ?
Klucz do sukcesu leży w umieszczeniu tagu w odpowiednim miejscu w dokumencie HTML. Powinien on znaleźć się w sekcji Twojej strony, najlepiej jako jeden z pierwszych elementów po otwierającym tagu . Dzięki temu przeglądarka wie, jak interpretować znaki na stronie, zanim jeszcze zacznie renderować jej właściwą treść. Oto przykład, jak to powinno wyglądać:
Moja strona z polskimi znakami
Witaj na mojej stronie! Tutaj znajdziesz polskie znaki: ą, ę, ć, ł, ń, ó, ś, ź, ż.
Jak widzisz, tag znajduje się tuż po otwierającym . To jest standardowa i najbardziej efektywna praktyka.
Struktura pliku HTML: Dlaczego umieszczenie meta tagu w sekcji jest kluczowe?
Sekcja dokumentu HTML jest przeznaczona na metadane informacje o stronie, które nie są bezpośrednio wyświetlane w przeglądarce, ale są kluczowe dla jej działania i interpretacji. Deklaracja kodowania znaków jest jedną z najważniejszych informacji, jakie przeglądarka musi poznać na samym początku. Umieszczając w , dajesz przeglądarce jasną instrukcję, jak ma odczytać wszystkie kolejne znaki w dokumencie. Gdyby ten tag znalazł się później, przeglądarka mogłaby już zacząć renderować tekst, używając domyślnego (i często błędnego) kodowania, co skutkowałoby pojawieniem się "krzaczków" zanim jeszcze zdążyłaby natrafić na właściwą deklarację. Zawsze pamiętaj: im wcześniej przeglądarka pozna kodowanie, tym lepiej.
Gotowy szablon startowy HTML z poprawnie ustawionym kodowaniem
Dla wygody przygotowałem minimalny szablon HTML5, który możesz skopiować i użyć jako punktu wyjścia dla swoich projektów. Zawiera on już poprawnie zadeklarowane kodowanie UTF-8 oraz podstawową strukturę, która zapewni prawidłowe wyświetlanie polskich znaków od samego początku:
Tytuł Twojej strony
Witajcie na mojej stronie!
To jest przykładowy tekst z polskimi znakami: ą, ę, ć, ł, ń, ó, ś, ź, ż.
Pamiętaj, aby zawsze używać UTF-8 dla spójności.
Deklaracja to nie wszystko! Zapisz plik z poprawnym kodowaniem
Wielu początkujących programistów popełnia błąd, myśląc, że samo dodanie tagu rozwiąże wszystkie problemy. Niestety, to tylko połowa sukcesu! Równie ważne, jeśli nie ważniejsze, jest to, aby sam plik HTML został fizycznie zapisany w kodowaniu UTF-8. Jeśli deklaracja w HTML mówi "UTF-8", ale plik jest zapisany np. w Windows-1250, przeglądarka nadal będzie miała problem z poprawnym wyświetleniem znaków. To jakby mówić w jednym języku, a pisać w innym efekt będzie niezrozumiały. Na szczęście, większość nowoczesnych edytorów kodu domyślnie używa UTF-8, ale warto wiedzieć, jak to sprawdzić i ewentualnie zmienić.
Jak sprawdzić i ustawić kodowanie UTF-8 w popularnych edytorach (VS Code, Notepad++, Sublime Text)?
Oto krótkie instrukcje, jak upewnić się, że Twój plik jest zapisany w kodowaniu UTF-8 w najpopularniejszych edytorach kodu:
-
Visual Studio Code (VS Code):
- Na dolnym pasku statusu (po prawej stronie) znajdziesz informację o bieżącym kodowaniu pliku (np. "UTF-8").
- Aby zmienić kodowanie, kliknij na tę informację, a następnie wybierz "Save with Encoding" (Zapisz z kodowaniem) i z listy wybierz "UTF-8".
-
Notepad++:
- W menu "Kodowanie" (Encoding) zobaczysz zaznaczone bieżące kodowanie.
- Aby zmienić, wybierz "Kodowanie" > "Konwertuj na UTF-8" (Convert to UTF-8). Pamiętaj, aby po konwersji zapisać plik.
-
Sublime Text:
- W menu "File" (Plik) znajdź opcję "Save with Encoding" (Zapisz z kodowaniem).
- Wybierz "UTF-8". Jeśli plik jest już w UTF-8, zobaczysz to zaznaczone.
Zawsze upewnij się, że po zmianie kodowania pliku, zapisujesz go, aby zmiany zostały zastosowane.
Pułapka Notatnika Windows: Prosta instrukcja, jak uniknąć najczęstszego błędu początkujących
Notatnik Windows to proste narzędzie, często używane przez początkujących do szybkiej edycji kodu. Niestety, jest to również źródło wielu problemów z "krzaczkami". Domyślnie Notatnik może zapisywać pliki w kodowaniu innym niż UTF-8 (np. ANSI, które często odpowiada Windows-1250 dla języka polskiego). Aby uniknąć tej pułapki, postępuj zgodnie z poniższą instrukcją podczas zapisywania pliku w Notatniku:
- Wybierz "Plik" (File) > "Zapisz jako..." (Save As...).
- W oknie dialogowym "Zapisz jako" znajdź pole "Kodowanie" (Encoding) na dole.
- Rozwiń listę i wybierz "UTF-8".
- Zapisz plik.
To małe, ale kluczowe działanie zapewni, że Twój plik będzie zgodny z deklaracją .
Różnica między UTF-8 a UTF-8 z BOM co wybrać i dlaczego?
Podczas zapisywania pliku w niektórych edytorach możesz natknąć się na opcję "UTF-8" oraz "UTF-8 z BOM" (Byte Order Mark). Czym jest BOM? To specjalny, niewidzialny znacznik umieszczany na początku pliku, który informuje programy o kolejności bajtów w kodowaniu UTF-8. W kontekście stron internetowych zazwyczaj preferowane jest czyste UTF-8 bez BOM. Dlaczego? Ponieważ BOM może czasami powodować nieoczekiwane problemy, takie jak puste linie na początku dokumentu, błędy parsowania w niektórych językach skryptowych (np. PHP) lub problemy z nagłówkami HTTP. Większość nowoczesnych przeglądarek i serwerów doskonale radzi sobie z czystym UTF-8, więc wybór opcji bez BOM jest bezpieczniejszy i bardziej uniwersalny.
Co robić, gdy podstawowe metody zawodzą?
W większości przypadków zastosowanie się do powyższych wskazówek czyli dodanie i zapisanie pliku w UTF-8 rozwiąże problem "krzaczków". Jednak czasami, choć rzadko, problem może być bardziej złożony. W mojej praktyce spotkałem się z kilkoma scenariuszami, gdzie winne były inne czynniki. Poniżej przedstawiam najczęstsze z nich i sposoby ich rozwiązania.
Problem z czcionką? Sprawdź, czy Twój font na pewno obsługuje polskie znaki
Nawet jeśli kodowanie jest ustawione poprawnie, problem z "krzaczkami" może pojawić się, jeśli używana przez Ciebie czcionka (font) po prostu nie zawiera glifów dla polskich znaków diakrytycznych. Nie wszystkie czcionki są stworzone równe niektóre są zaprojektowane tylko dla podstawowego alfabetu łacińskiego. Jeśli używasz niestandardowej czcionki, np. pobranej z internetu, upewnij się, że w jej opisie jest informacja o wsparciu dla "Latin Extended", "Central European" lub "Polish characters". Jeśli czcionka nie ma tych znaków, przeglądarka może próbować zastąpić je innymi, co często prowadzi do wyświetlania kwadratów, znaków zapytania lub innych nieprawidłowych symboli. W takim przypadku rozwiązaniem jest po prostu zmiana czcionki na taką, która wspiera polskie znaki.
Jak poprawnie importować fonty z Google Fonts z obsługą `latin-extended`?
Google Fonts to fantastyczne źródło darmowych czcionek, ale i tutaj trzeba być ostrożnym. Podczas importowania czcionek z Google Fonts, upewnij się, że wybrałeś odpowiednie podzbiory znaków. Dla języka polskiego kluczowe jest zaznaczenie opcji latin-extended (lub podobnej, w zależności od czcionki). Oto przykład, jak to wygląda w kodzie CSS, gdy importujesz czcionkę:
@import url('https://fonts.googleapis.com/css2?family=Open+Sans:wght@400;700&display=swap&subset=latin,latin-extended');
Zwróć uwagę na fragment &subset=latin,latin-extended. To on informuje Google Fonts, aby dostarczyło pliki czcionek zawierające rozszerzony zestaw znaków łacińskich, w tym polskie "ogonki". Bez tego, nawet jeśli w deklaracji HTML masz UTF-8, czcionka może nie mieć potrzebnych glifów, a problem "krzaczków" powróci.
Gdy winny jest serwer: Jak nagłówki HTTP mogą nadpisać Twoje ustawienia w HTML?
W rzadkich przypadkach problem z kodowaniem może wynikać z konfiguracji serwera WWW. Serwer, zanim wyśle plik HTML do przeglądarki, może dodać do niego nagłówki HTTP, w tym nagłówek Content-Type, który zawiera informację o kodowaniu znaków (np. Content-Type: text/html; charset=ISO-8859-1). Nagłówek HTTP wysłany przez serwer ma wyższy priorytet niż deklaracja w pliku HTML! Oznacza to, że nawet jeśli w HTML wszystko jest poprawnie ustawione na UTF-8, serwer może wymusić inne kodowanie, co spowoduje "krzaczki".
Jeśli podejrzewasz, że to serwer jest winny, możesz spróbować zmienić jego konfigurację. Dla serwerów Apache często robi się to za pomocą pliku .htaccess. Możesz dodać do niego następującą linię:
AddDefaultCharset UTF-8
Lub, jeśli problem dotyczy konkretnych typów plików:
AddCharset UTF-8 .htm .html .php .js .css
Pamiętaj, aby po każdej zmianie w pliku .htaccess sprawdzić, czy strona działa poprawnie, ponieważ błędy w tym pliku mogą unieruchomić całą witrynę. Jeśli nie masz dostępu do konfiguracji serwera lub nie czujesz się pewnie z edycją .htaccess, skontaktuj się z administratorem swojego hostingu powinien być w stanie pomóc.
Alternatywne i historyczne metody kodowania
Zawsze polecam stosowanie UTF-8 jako standardu, ale warto znać również inne, historyczne lub alternatywne metody kodowania, choćby po to, by zrozumieć, dlaczego są one mniej praktyczne lub przestarzałe. Czasami możesz natknąć się na nie w starszych projektach.Czym są encje HTML (ó , ą ) i kiedy ich użycie ma jeszcze sens?
Encje HTML to specjalne sekwencje znaków, które reprezentują inne znaki, zwłaszcza te, które mają specjalne znaczenie w HTML (jak < czy &) lub te, które są trudne do wpisania z klawiatury. Dla polskich znaków diakrytycznych również istnieją encje, na przykład:
-
ąlubądla 'ą' -
ęlubędla 'ę' -
ćlubćdla 'ć' -
łlubĺdla 'ł' -
ńlubńdla 'ń' -
ólubódla 'ó' -
ślubśdla 'ś' -
źlubźdla 'ź' -
żlubżdla 'ż'
Jak widać, używanie encji dla całego tekstu jest niezwykle niepraktyczne i czasochłonne. Tekst staje się nieczytelny w kodzie źródłowym i trudny do edycji. Dlatego też, w dobie UTF-8, encje HTML dla polskich znaków są stosowane bardzo rzadko właściwie tylko w wyjątkowych sytuacjach, gdy inne metody zawiodą, lub dla pojedynczych znaków specjalnych, które z jakiegoś powodu sprawiają problem, a nie chcemy zmieniać globalnego kodowania dokumentu. Zdecydowanie odradzam ich masowe użycie.
Dlaczego należy dziś unikać przestarzałych standardów jak `windows-1250`?
Wspomniane wcześniej kodowania, takie jak windows-1250 czy ISO-8859-2, były kiedyś standardem dla języka polskiego. Dziś jednak ich użycie w nowych projektach jest zdecydowanie odradzane. Powodów jest kilka:
- Ograniczony zasięg: Obejmują one tylko wybrane zestawy znaków, co oznacza, że strona napisana w Windows-1250 będzie miała problemy z wyświetlaniem znaków z języka rosyjskiego, chińskiego czy arabskiego. UTF-8 radzi sobie z tym bez problemu.
- Brak uniwersalności: Zwiększa to ryzyko problemów z kompatybilnością na różnych systemach operacyjnych, przeglądarkach czy urządzeniach, które mogą mieć inne domyślne kodowania.
- Przestarzałość: Są to standardy historyczne, nieprzystające do współczesnych, globalnych potrzeb internetu.
Trzymaj się UTF-8. To uniwersalne, przyszłościowe i bezproblemowe rozwiązanie, które eliminuje konieczność martwienia się o specyficzne kodowania dla różnych języków.
Twoja checklista: Strona bez "krzaczków" w 3 krokach
Podsumowując, aby Twoja strona internetowa zawsze wyświetlała polskie znaki diakrytyczne poprawnie i bez żadnych "krzaczków", pamiętaj o tych trzech kluczowych krokach. To moja osobista checklista, którą polecam każdemu deweloperowi.
Krok 1: Wstaw w sekcji
Upewnij się, że w sekcji Twojego dokumentu HTML znajduje się tag . Najlepiej umieść go jako pierwszy element po otwierającym tagu , aby przeglądarka jak najszybciej wiedziała, jak interpretować znaki.
Krok 2: Zapisz plik HTML w kodowaniu UTF-8
Sprawdź i upewnij się, że sam plik HTML jest fizycznie zapisany w kodowaniu UTF-8 w Twoim edytorze kodu. Pamiętaj, aby wybrać opcję "UTF-8" bez BOM, jeśli taka jest dostępna. To kluczowe, aby deklaracja w kodzie była zgodna z faktycznym zapisem pliku.
Przeczytaj również: CSS w HTML: 3 metody, kaskada, specyficzność. Stylowanie bez błędów
Krok 3: Używaj czcionek wspierających polskie znaki (`latin-extended`)
Jeśli używasz niestandardowych czcionek, zwłaszcza tych z Google Fonts, zawsze upewnij się, że importujesz je z rozszerzonym wsparciem dla języków łacińskich (np. opcja latin-extended). To gwarantuje, że czcionka zawiera wszystkie niezbędne glify dla polskich znaków diakrytycznych.